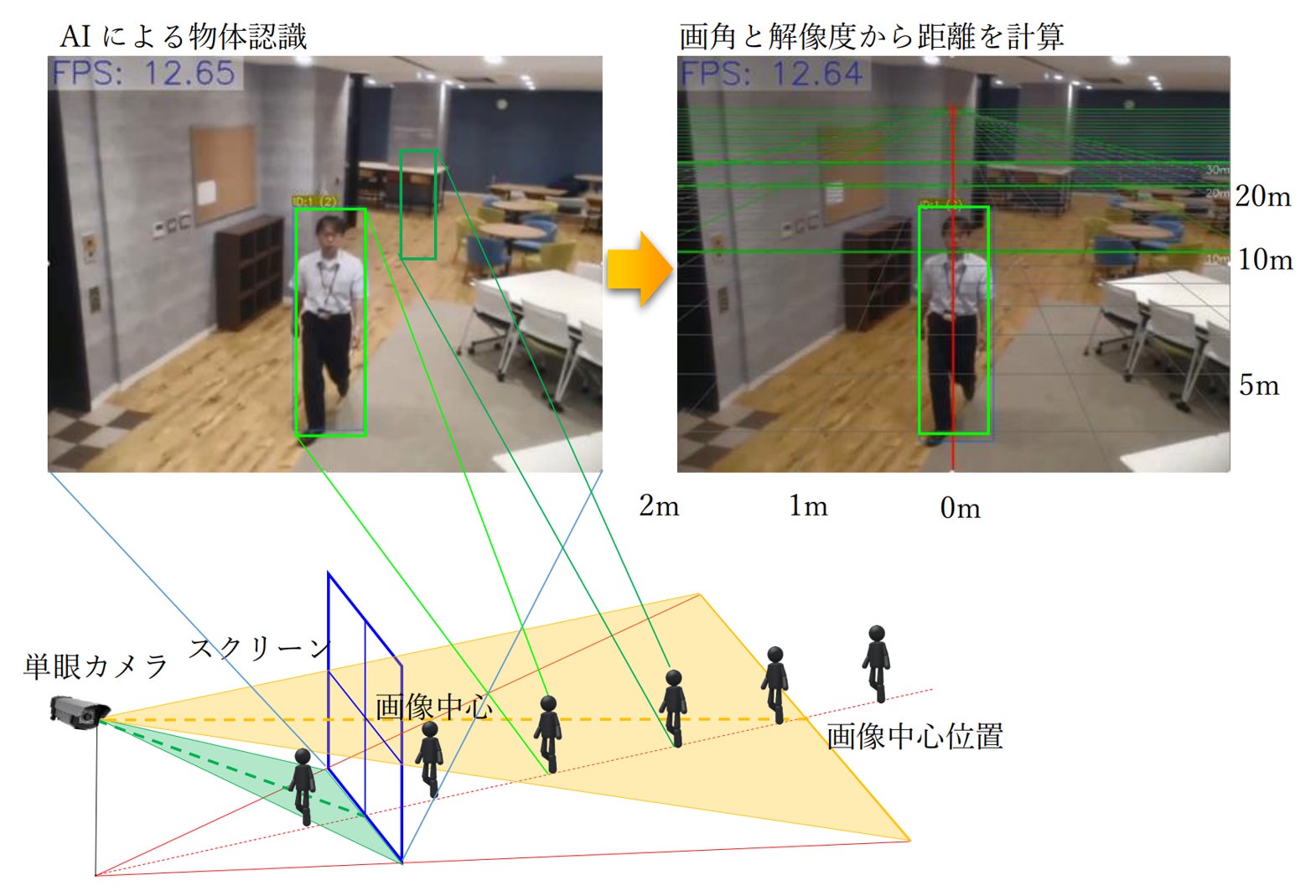
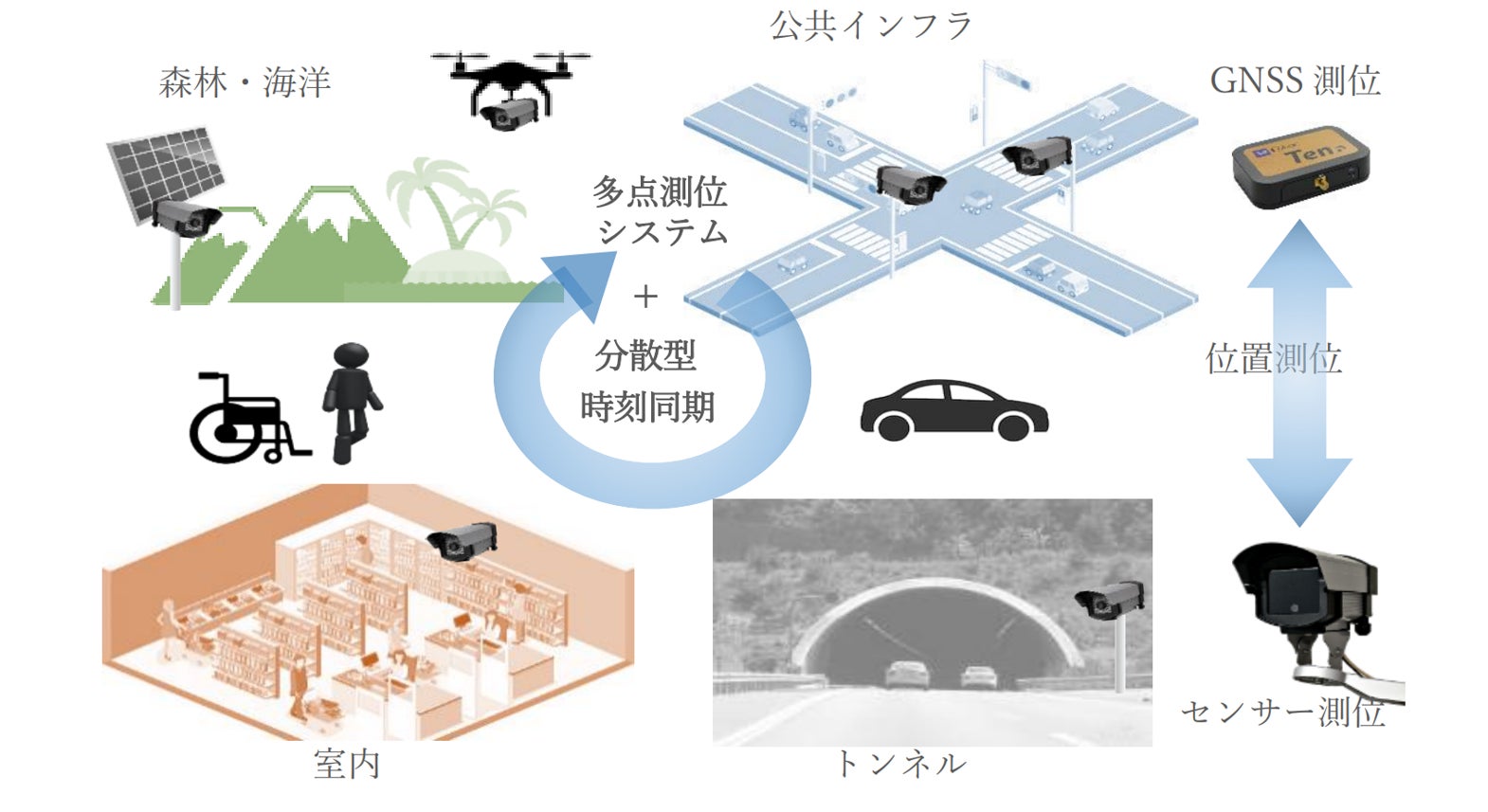
自分のアクションには何かを変える影響力なんてない。「自己効力感」が低い日本の空気を変えていくZ世代中心のスタートアップLiquitousのメンバーがみる今と描く未来とは。
1990年中盤以降生まれの「Z世代」が、いよいよ社会で活躍をはじめている。彼らはどんな社会背景を持って育ち、どのような価値観を持っているのだろうか。
今回話を聞いたのは、オンライン参加型合意形成プラットフォーム「Liqlid(リクリッド)」の開発・社会実装をすすめる株式会社Liquitous(リキタス)に所属するZ世代の3人だ。前編では民主主義のDXに挑むビジネスパーソンとしての側面を聞いたが、後半では主に3人だけでなく同世代を俯瞰して感じる共通点やそれをつくってきた社会背景について話を聞いた。
前編:「私達がやらないと国がなくなってしまう」Z世代が民主主義のDXに挑む理由
相手にログインできたらいいのに
── 前編で栗本さんと藤井さんは、小さい頃から政治に興味があったと話していましたね。どうして興味を持っていたのでしょうか。
栗本 私の関心は、政治というよりも統治でした。私は両親が共働き、かつ海外出張の多い家庭で育ちました。両親はよく海外から電話をくれたんです。バングラデシュ、シンガポール、アメリカ…電話が来るたびに、両親がいる国を図鑑で調べていました。
小学校に入学する頃、ふと「図鑑の中に自分の国がほしい」と思ったんです。そこで国旗や憲法、貨幣などを自分なりに考えて「国ごっこ」を始めたんです。
── 「国ごっこ」って、どんなことをしていたんですか?
栗本 コピー用紙を切って紙幣を、段ボールでパスポートをつくってみたり、インターネットでさまざまな憲法を調べてつくってみたり。まずは家族5人を国民にして、金魚のきんちゃんが6人目でした(笑)。国名も考えていましたよ。最初は「ヒロ王国」という王制の国でしたが、途中で共和制に変更したり、大統領選挙もやってみたりして(笑)。小学校では同級生と一緒に「会社ごっこ」もやっていました。メンバーを集めて、名刺をつくって。雑誌をつくって、独自の貨幣でビジネスの真似事をしていたんです。
中学校1年生ではクラスを代表して、生徒会に意見を伝える「生徒議会議員」に立候補しました。「議会」や「議員」というキーワードに惹かれたことがきっかけでしたが、実際に生徒会活動に関わることで「民主主義ってこういうことか」と実感。そこで、2年生からは生徒会に入り、中高合わせて副会長を3回、生徒会長もやりました。高校では全国的な生徒会のネットワークで、中心的な役割を果たすこともありました。日本全国の生徒会から制度の問題点を集めて、改善していくための議論をしたり、自分たちではどうにもならないことは国や文科省に提言することもありました。
── 「ごっこ」から、徐々に実際の政治や行政へと移っていったんですね。藤井さんはどうでしょう。
藤井 僕は栗本みたいに国を作った経験はありませんが(笑)、両親の仕事に影響を受けた点は一緒です。母親は障がいを持った子どものヘルパー、父親は生活保護が必要な人の相談窓口をやっていました。社会にはさまざまな事情を持つ人や社会的に弱い立場にいる人がいることを小さなころからなんとなく知っていたし、そういった人たちと僕たちの環境の間には格差があることもわかっていました。
でも、日本には民主主義という仕組みがあって、みんなに選ばれた政治家が代表者として政治をしている。本来であれば、政治家とはさまざまな課題を解決できるすばらしい仕事だと思うんです。でも、すべての人がそうとはいいませんが、不正や汚職の報道が絶えませんし、世間もそういったマイナスイメージに引っ張られている。本来の民主主義の仕組みも、政治の役割も十分に機能できていない。そんな状況が気になり、次第に政治や行政への関心が高まってきました。

── 栗栖さんは集団心理に興味を持っていたと話していましたね。これはなぜだったのでしょうか。
栗栖 私も中学時代に生徒会の役員を務めており、その経験が大きいです。栗本のように学外の人とコミュニケーションをとっていたわけではないですが、学内で大人数の意見をまとめることが多くありました。学校という小さなコミュニティであっても多数派・少数派があり、まとめるのは簡単なことではありません。
また、コミュニケーションを取っていると、相手の真意がわからなかったり、自分の真意を伝えられなかったりすることも多い。そもそも自分が何を考えているかをメタ認知できていないこともあります。「相手にログインできたらいいのに」とよく考えていました。
── 相手にログイン?
栗栖 自分が誰かとコミュニケーションを取る時、目の前に見える相手の外側と、相手の心の奥にある内面は全然別のものだと思うんです。だから相手にログインして言葉にしない思いをわかることができればと。
こうしたことをより深く考えていくと、思考は社会の影響やフィルタリングの結果にも影響を受けていることに気付きました。そもそも環境のせいで本音が言えないときもあれば、本人が気づいていない本音がある場合もあるでしょう。そこを越えるためには個人に向き合うよりも社会全体と向き合ったほうがよいのではないかと思うようになったんです。
フレームワークは共通でも、それを通じて見ているものは違う
── 相手にログインという発想を中学生から持てるのがZ世代らしさかもしれないと思いました。みなさんは「Z世代」「Z世代らしさ」をどのように捉えていますか?
栗本 Z世代と言っても、世代共通の考えが定まっているわけではないし、人によってずいぶんと価値観が異なると思います。「この世代はこうだ」なんてラベリングできるようなものではない。例えば、Z世代はジェネレーションレフト(左派世代)なんて言われることもありますが、私は一概にそうとは思いません。ただその一方で、世の中を見るときのフレームワークはかなり共通していると思うんです。私が感じるフレームは主に3つです。

栗本 1つは、デジタルとアナログに関して。年上の人と話すと、「デジタル or アナログ」という二者択一にこだわる人が非常に多いですが、Z世代はデジタルかアナログかということにこだわりはないんです。純粋に「そのとき大切な手段」を選ぶだけ。
2つ目は、多様性について。これも上の世代の方と話をすると「多様性」を一つの価値観のように捉えている人が多いと感じます。でも、Z世代の多くは多様であることを前提として世の中を捉えている。
3つ目は、社会に対するある種の無力感について。私たちの世代は、世の中が今の延長線上では続かないと思っているし、何もしなければ現状維持はできるかもしれないけれども、良くなるとも思っていない。甘い期待や夢を持っていないんです。その結果として、人によっては刹那的になるかもしれないし、あるいは何とかしなきゃと思うかもしれない。
これらは、Z世代の多くが共通して持っているフレームワークだと思うんです。しかし、このフレームワークを通して何を見ているかというのは、かなり人によって違うのではないのかなという印象があります。
栗栖 栗本がいうところの多様性の話とも関連しますが、周りとの比較の仕方にZ世代の共通性があると思っています。過去も現在も集団生活が基本なので、Z世代も他の世代と同じように自分と他人を比較します。ただし、上の世代は周りと比べた時にいかに自分が「劣っていないか」を比較のものさしにしていたように思うんです。しかしZ世代は「何がぬきんでているか」という視点で周りと比べているのではないか、と。
一昔前のインターネットカルチャーは匿名が基本でした。自分の顔はもちろん、多くの場合は本名も出さない。でも今は自分の顔も声も出して、自分のパーソナリティをさらけ出して、人の共感を得ようとしています。だから自分のオリジナリティを探す方向に意識も向いている人が多いのかもしれません。この傾向は良くも悪くもリアクションされることが生きる上で重要なウェイトを占めてしまい、個性的であることが強迫観念になっていることもまた、Z世代の共通点だと思います。

栗本 共感の測り方も独特かも知れないです。少し上の世代は、いいね数やリツイート数など、定量的でわかりやすい数値を基準にしていました。しかし、Z世代は必ずしも定量的ではありません。圧倒的な数にリーチはできなくてもいいけど、わかる人には深くわかってほしいというような。
藤井 個性的という意味では、就活への価値観もずいぶんと変わってきていると思います。どんな仕事に就きたいかではなく、自分は人生で何をしたいかという考え方です。例えば、YouTuberとしてこれまで仕事にならなかったような自分の好きなことを仕事にもできるし、昔からあるような大きな会社の一社員として働くこともできる。いろんな選択肢ができたことで、仕事に就くことより手前から考えるようになった。
── 藤井さんの周囲にはどのように就活を考えている人が多いですか。
藤井 僕は『資本主義と民主主義の終焉――平成の政治と経済を読み解く』という本を書いた水野和夫先生のゼミにいるんですが、右肩上がりの経済成長が頭打ちになることを前提に考えてる人は少なくないと思います。周りには、演劇に進んだり、休学してみたりと、まずはお金よりも自分のやりたいことを選んだ人も多いですね。ある程度のお金を稼ぐ方法はいろいろあるから、それらを活用しながら自分のやりたいことをしようと。
栗本 藤井の言うような経済的な感覚や仕事への向き合い方には、実は地域差があると思います。仕事で地方を訪れて同世代と話すと、情報としては触れながらも周囲の価値観が変わっていないので結果的に旧来的な価値観が再生産されてしまう。情報が簡単に得られるようになった分、地方と都市部の価値観の差は広がっているという側面もあると思います。
栗栖 私は高校卒業するまで広島にいたので、地方と都市の差は強く感じます。都市のほうが圧倒的に選択肢が多い。とくに感じたのは、進路指導やサポート体制です。私はAO入試で大学受験をしたのですが、面接や志望理由書などの対策環境は圧倒的に都市のほうが有利だと感じました。そもそもAO入試を選ぶ学生の数が少ないですし、私の周囲には「そんな受験の仕方は認めない」というような人もいました。こうした教育や社会参加に対するハードルはあります。
栗本 高校時代に全国の同世代と話し、こうした地域における差を感じたこともまた、今の事業の原動力になっています。いくら都市で先端的な議論をしても、それが都市だけで終わってしまえば、社会に実装されたとは言えないと思うのです。
それぞれが描いている未来について
── 最後に、3人がそれぞれどんな未来を描いているかについて、教えてください。
栗栖 地方であろうと都市であろうと、どんな社会的な背景があっても、人それぞれが動き方や考え方を自由に決めることができる、その手段が用意されているのが社会のあるべき姿だと思っています。
ですから、私たちが進めている民主主義のDXの方法にすべての国民や市民を押し付けて参加させるようなものであってはならないと思うんです。あくまでも行政と市民のコミュニケーションの選択肢の一つとして、私たちの業務が浸透していってほしいと思っています。そのためにも、インフラと胸を張って言えるようなレベルまで整えていかねばならならないですね。

藤井 例えば政治や社会への関心度だって、人それぞれだとは思っています。投票率が低いことも、いますぐ変えられることではない。僕たちがやっているのは、関心を持った人が自分の意見を伝えることができる仕組みづくりです。伝えるべきものがあるときはきちんと伝わる、伝えた声が行政などに反映される市民参加の仕組みの前提が整備されることで未来がすこしでも良くなればと思っています。
栗本 私たちは「一人ひとりが影響力を発揮できる社会」を目指しています。影響力とは、例えば誰かが国や行政に届けたい声があれば、届けることができる。あるいは、この社会を変えたいと思ったときに、社会を変えることができる、ということ。つまり、一人ひとりが「自分のアクションは何かを変える影響力がある」と実感することです。
日本では、若い方を中心に自己効力感が低いことがさまざまな調査などで明らかになっています。自己効力感とは、自分がある状況において「必要な行動をうまく遂行できる」と自分の可能性を認知していること。現状では多くの人が「自分の1票では世の中は変わらない」「自分がデモに参加したところで意味がない」と思っている。
これを解くには、市民の参加の仕方や仕組みづくり、ひいては統治の在り方自体を考え直さなければならない。つまり、「民主主義」という大きなキーワードを考え直す必要があると思うんです。
もちろん、それはすぐにできることではありません。だからこそ、事業としても持続可能なものにしなくてはなりませんし、一つひとつ着実に変化を積み重ねていくことが必要なんです。
プロフィール/敬称略
※プロフィールは取材当時のものです
- 栗本拓幸(くりもと・ひろゆき)
-
1999年生まれ。株式会社Liquitous 代表取締役CEO。市民の社会参加/政治参加にかかる一般社団法人やNPO法人の理事、地方議員コンサルタントなどとして活動。現場の声や自らの経験をもとに、デジタル空間上に、市民と行政をつなぐ「新しい回路」の必要性を確信し、2020年2月にLiquitousを設立。
- 藤井 海(ふじい・かい)
-
2000年生まれ。株式会社Liquitousリサーチャー・オペレーター。法政大学法学部政治学科を休学中。中学生の頃、デンマーク海外派遣に参加し、日本とデンマークの教育や政治などの社会システムの違いに衝撃を受ける。以来、政治に関心をもち、大学では主に経済分野から政治を学ぶ。
- 栗栖翔竜(くりす・しょうた)
-
2000年生まれ。株式会社Liquitousリサーチャー・コミュニケーター。慶應義塾大学総合政策学部に在学中。集団での研究活動などの経験から、「コミュニケーションのあり方」に関心を持つ。以来、郊外のコミュニティ運営を支援する学生団体の設立等に寄与したのち現職。大学では主にメディア政治学と精神分析学を学ぶ。
関連リンク
からの記事と詳細 ( 多様性を一つの価値観とは捉えない?民主主義のDXに挑むZ世代からみた同世代 | 株式会社リクルート - リクルート )
https://ift.tt/Hg2Nb1C