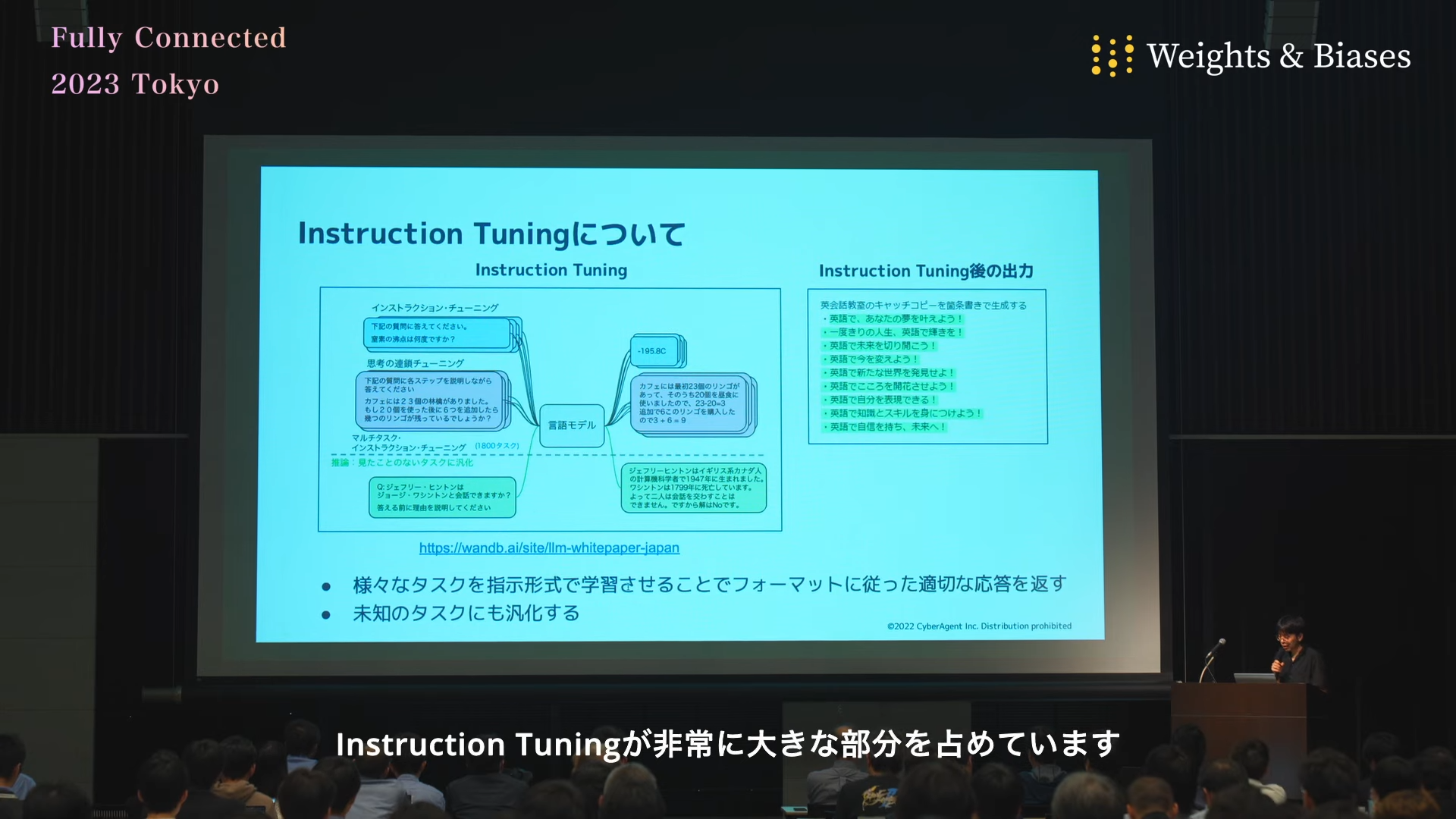
今のサイバーセキュリティは「侵入されること」が前提
鈴木暢氏:みなさま、こんにちは。このセッションでは「ログの監視分析とSOCサービス、組み合わせの勘どころ」と題して、ログの分析・監視環境をどのように構成すべきかという情報提供と、ALogを活用した弊社のマネジメントセキュリティサービスについてご紹介いたします。私は、ブロードバンドセキュリティの鈴木と申します。30分弱、お付き合いくださいますようよろしくお願い申し上げます。
では、まずはログ監視・分析の必要性についてお話いたします。みなさまには、釈迦に説法になろうかとは思うんですけれども、本日のお話の前提としてお聞きいただければと存じます。
そもそも、なぜログの監視・分析が必要なのかを整理していきたいと思います。まず一昔前のサイバー攻撃対策では、不正侵入の対策に終始する傾向がございました。例えばファイアウォールやWebフィルタ、IPS、アンチウイルスのツールの導入が具体的な対策手法になっていたかと思います。
これはどういう考え方かと申しますと、「侵入されないこと」が前提でありまして。侵入・被害を受けた状態からの対策は、残念ながら想定していないのが一昔前の実情かなと思っております。
対して現在は、サイバー攻撃自体が非常に巧妙になってきており、みなさまも報道等でご存知のことかと思いますけども、もはや本気のサイバー攻撃を食らったら侵入されることを覚悟しなければならない。そういった状況まできていると考えております。
このような状況を鑑みて大事になってくるのは、この「侵入されること」ですね。これを前提として考えることが、必要な対策になってくるかと存じます。
サイバー攻撃の6つのフェーズ
図示しているのは攻撃者の手口です。これはサイバーキルチェーン(サイバー攻撃が行われる過程をモデル化したもの)や、MITRE ATT&CK(実世界で観測されたサイバー攻撃の手法をフェーズごとに分類してまとめたもの)などで示されている攻撃の手順を簡単に表現したものになります。

「①不正侵入」から、被害を受ける「⑤情報窃取」「⑥破壊」までに、3つほどステップがあるということがわかるかと思います。②から④、「②実行」「③永続化」「④防御回避」ですね。攻撃者がこういった行動をしている間に気づくことができれば、被害を受ける前に攻撃者の行動を止められるというような効果が期待できるかと思います。
仮に⑤とか⑥、情報窃取か破壊までいったとしても、早めに気がつけば攻撃者が完全に目標を達成する前に行動を止められる可能性もあります。いずれにしても侵入されることを前提に対策を考えることで、被害を最小化できます。
では被害を最小化するために、侵入されることを前提としたサイバー攻撃対策としては、どのようなものがあるかを考えていきたいと思います。例えば本日取り上げるログ監視・分析もその1つではありますが、さまざまな対策手法がございます。
EDRやNDR、XDRといったソリューションの利用も手法の1つかと思います。これらの対策の共通的な特徴として、攻撃者の爪痕を網羅的に監視するというところがあります。EDR、NDR、XDR等々のツールは、それぞれに得手不得手があり、当然ながら守備範囲外の観点もございます。
そうしますと組織の特徴に合わせて、独自の監視・分析が必要になるポイントも出てくるかと思います。そういったソリューションを取りまとめたものが、このログの監視・分析です。結論から申しますと、侵入された時に被害を最小限に抑えるための対策として、ログの保管・監視が有効になってくるというところです。
ログの監視・分析の必要性についてご理解いただいたところで、ログの監視・分析が世の中でどのようなポジションにいるかというところを整理してまいりたいと思います。
サイバー攻撃への対策に必須となる「ログの監視・分析」
こちらにいくつか公的なガイドラインを例示しております。まずはみなさんご存知の、経済産業省が出しております「サイバーセキュリティ経営ガイドライン」を見ていきたいと思います。

このガイドラインは、経営者を対象としたサイバー攻撃への対策の原則と、責任部署への指示事項を10個の指示にまとめたものとなっております。この「指示5:サイバーセキュリティリスクに対応するための仕組みの構築」というところで、ログの監視・分析について触れております。
この経営ガイドラインは、現在バージョン3になっておりまして、ちょっと内容が抽象的になっていますけども。「防御だけでは不十分で、検知・分析が必要」という表現をされているところは同じ意味合いになります。
次に日本自動車工業会・日本自動車部品工業会の「自工会・部工会サイバーセキュリティガイドライン2.0版」を見ていきたいと思います。私どもは通称、自工会ガイドラインと呼ばせていただいております。こちらのガイドラインはどのような対策を、どのような優先度で対応すべきかというところを、非常にわかりやすく表現しています。
これは当然自動車産業向けにリリースされているガイドラインではありますが、私どもは、自動者産業といった製造業のみならず、さまざまな業種業体でサイバーセキュリティ対策をする際のガイドラインとして参考になるものと考えております。
長くなりました。この自工会ガイドラインに注目しますと、No.53とNo.145の2つにログ監視・分析に関する技術が具体的に示されております。「No.53:アクセスログは、安全に保管しアクセス制御された状態で管理されている」「No.145:ログを分析し、サイバー攻撃を検知する仕組みを導入している」と、非常に具体的に書かれていますね。
ほかにも、金融、官公庁、水道、交通、重要インフラ、地方自治体、中小企業、教育……とさまざまな分野でガイドラインが出ておりますが、この中でログ監視・分析に触れられていないガイドラインはないと言っても過言ではないと考えております。
したがって各種ガイドラインに示されているとおり、昨今ログ監視・分析がセキュリティ対策に必須であると、世の中的には認識されていると私どもは考えております。
「ログの監視・分析環境」を整備する時のポイント
次にログの監視・分析環境を構築する際の課題と解決策について、お話しさせていただければと思います。特にログの監視・分析環境の整備は、ほかのセキュリティソリューションにはない独特な課題があると考えております。
ここからはログの監視・分析環境を整備するために何が必要かと、その課題に対する解決策としてのSOCサービスの利用の勘どころについて述べてまいります。
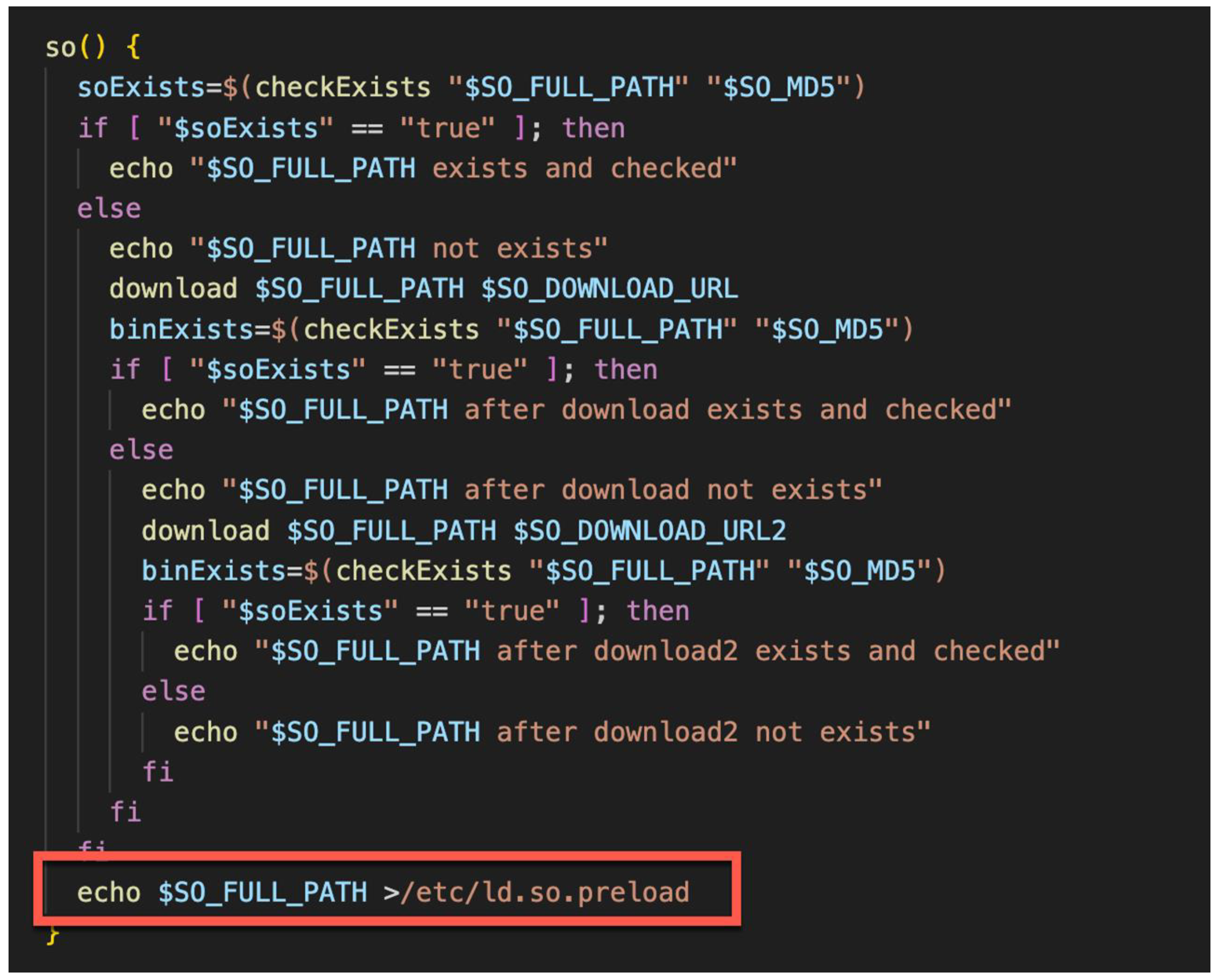
ではまずログの監視・分析環境に必要な要素のうち、重要なポイントを「導入時」と「運用時」の2つに分けて示しております。導入時ですが、まずログ収集対象を選定しなければなりません。システムにどのようなログがあって、それをどういうふうに収集するかというところですね。当然ながらログ収集ツールというものを導入する必要もございます。

そして、ログ収集の構成・設定ですね。ログ収集の対象によってどういうふうにログを収集するか、それからどういう設定をすればいいかというところは個々に違うわけで、そういったところに対応していく必要があります。
次にログ分析の方法の確立です。集めただけでは分析になりませんので、それをどうやって監視・分析していくかというところを考えていく必要がございます。次がアラート機能の実装ですね。分析した結果として「これは即時発報してほしい」というようなアラートを決めて、それを実装してまいります。
そのアラートが出てきたあとに、実際にそのアラートがどういう事象だったのかを監視・分析していく必要もございますので、そういった体制の構築も導入時の必要な要素かなと思っております。
ログを集めて分析し、得られた結果をどう判断するか
では運用時について、まずログ収集ツールの維持管理ですね。これはシステムを運用されているみなさま方も、当然だと思われているかと思いますけれども。ログ監視・分析環境の肝となります、ログ収集ツールを維持管理する必要がございます。
それから次が、ログ収集対象の増減対応ですね。ログ収集対象は当然ながら、システムを運用していると減ったり増えたりします。そういったところに対応して、適切にログ収集ツールにログが入ってくるようにしなければいけません。
それからログ監視・分析結果の重要度判断ですね。導入時に考えたログ分析方法、それから実装したアラート機能から出てくるアウトプットの結果ですね。それがどういった重要度を持っているのか、自分たちのシステムにどういう影響があるのかを元に、重要度を判断していく必要があります。
そのためにはログ監視・分析要員を教育する必要もございます。また攻撃手法も世の中が進むに当たってどんどん変わってまいりますので、ログ監視・分析内容の最新化にも対応していかなければならない。最も大事なのは、インシデントが発生した時の報告・対処方法ですね。こういったところにもリソースが必要です。
こちらをご覧いただくと、ログの監視・分析環境の導入・運用には多くのリソースが必要になるというところがわかるかと思います。
課題の根幹は「知識・技術」「リソース」「人材」
では次に導入時の要素と、よくある課題について整理してまいりたいと思います。先ほど、導入時にはさまざまなポイントがあるというお話をしました。
それぞれのログ収集対象を選定するのに、どういったログを集めれば監視・分析に効率的か。その導入に当たってはどういうツールが望ましいか、サーバーのスペックはどういったものが必要かなどですね。
ログ収集の構成設定については、特に収集する対象は現在業務に使われているものが非常に多くございますので、既存業務に影響しないようログを収集するにはどうするかというところも大事になってくるかと思います。
それからログ分析方法の確立ですね。多くの種類、多くの量のログを収集することになりますので、そういったところからどうやって攻撃を見つけるかというところですね。これを見つけるための手法と共に、大量のログから必要なポイントだけをピックアップするアラートをどうするかというところ。
それから体制を構築するに当たっては、ログ監視・分析スキルを持つ人材が必要になりますけれども、この人材は非常に今、希少と言われております。残念ながら採用も教育もなかなか厳しいと言われております。
こういったさまざまな課題が挙げられると思いますけれど、整理しますと課題の根幹は「知識・技術」、「リソース」、それから「人材」。こちらに帰結するものになるかと思います。
一朝一夕では乗り越えられない「課題」への対処法
では同じように、運用時の課題についても整理していきたいと思います。まずツールの維持管理。当然維持管理にもコストが必要になります。ログ収集対応の増減対応、新しい設備が増えた時にどう対応すればいいのか。

特に新しいシステムを導入する時に、そのログをどうやって収集するか。ノウハウがございませんので、それについても調査して対応しなければならないというところですね。
次に、見つけたイベントの重要度をどうやって判断するのか。どういう教育をすればいいのか。当然コストもかかります。
それからログ監視・分析内容の最新化。最新動向をどうやって追いかければいいのか。インシデント発生時の報告・対処については、そもそもどういうふうに対応すればいいのかといった課題がございます。
これも先ほどの導入時と同じように整理しますと、課題の根幹は「知識・技術」「リソース」「人材」に帰結することになろうかと思います。
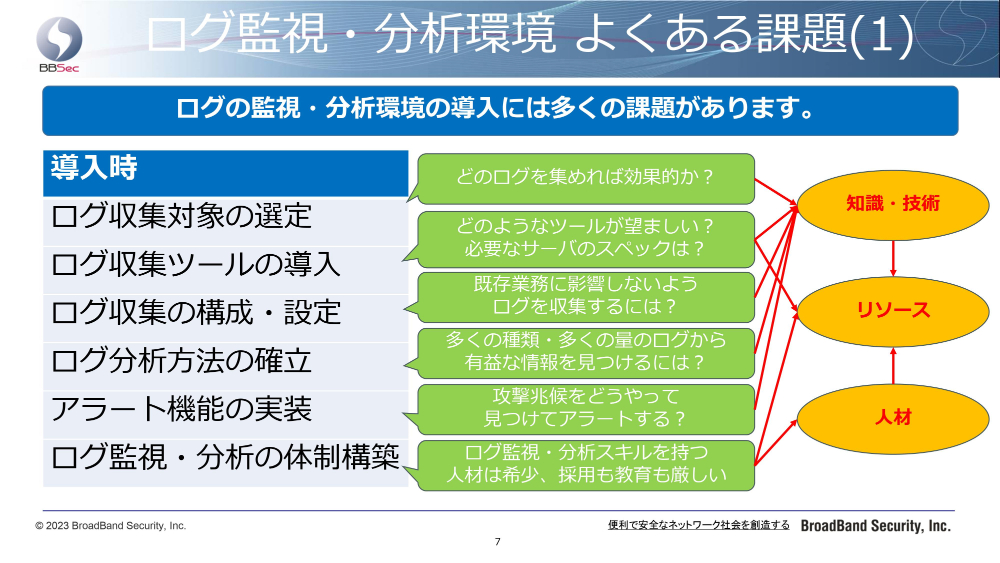
ここまでお話ししてきまして、あらためてログ監視・分析環境の整備の課題について整理いたします。まず課題①、「知識・技術」と先ほどまとめて申し上げたところが1つです。保全すべきログの種別、監視・分析方法がわからないという課題。
課題②、これは「リソース」ですね。いつ発生するかわからないイベントを常時監視するリソースがないというところ。それから課題③、「人材」ですね。検出したイベントを元に重要度を判断したり、対策方法を検討する専門的な人材がいないというものになります。
これらの課題は、自組織では一朝一夕で解決するものではないと考えております。したがいまして私どもとしては、「専門家の協力を得て解決する方法」を推奨する次第でございます。
自社でセキュリティ対策を実施するメリットとデメリット
専門家の協力を得て解決する方法は、大きく分けて3つあると考えております。まず1つがコンサルティングサービスの利用ですね。もう1つがアウトソーシングサービスの利用。3つ目は専門人材の派遣を要請するという方法があろうかと思います。
ここで3つ目の「専門人材の派遣を依頼する」というところなんですが、当然ながら専門人材は高度な能力が必要となってまいります。現状は業界全体で人材不足のために実現性が低い状況になっており、現実的な方策はコンサルティングを受けるか、アウトソーシングするかの2択になろうかと思います。
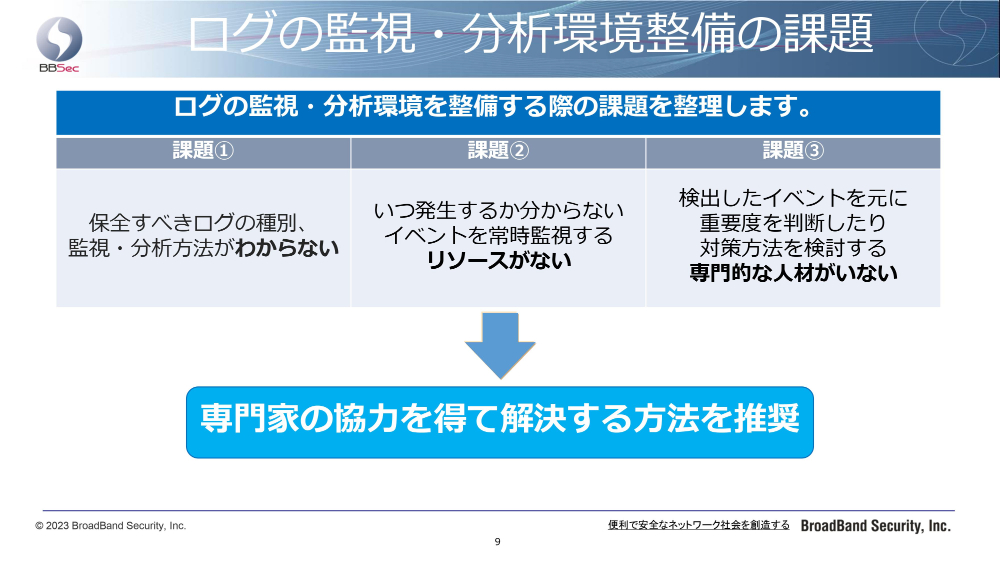
先ほどまでのお話を踏まえて、具体的にどのように課題を解決していくべきか。どういうふうに環境を整備していくか。環境整備の方式と、それからログ監視・分析環境の整備ポイントですね。これをマトリックス化し、メリット・デメリットを整理いたしました。
「自組織で整備」は、自分の組織でログ監視・分析環境を整備するという、非常にオーソドックスな手法となります。まずログの収集・保全は自組織で設備を用意します。
ログ分析も自組織の設備を利用しつつ、自組織にSOC(IT機器やネットワーク、デバイス、サーバーなどの監視と分析・サイバー攻撃の検知を行うセキュリティ部門・チーム)を作ってここで分析する。重要度判断も自組織のSOC、インシデント対応も自社CSIRT(実際に起こったセキュリティインシデントの対応を担当する部門・チーム)を使うと。
メリットとしては、最適な対応が可能です。当然自組織ですべてを整備しますので、自組織に最適な対応が可能となります。デメリットとしては自組織に高スキル人材が必要です。この高スキル人材が今、なかなか枯渇していると言われております。
それから最適を追求すると、どうしても高コストになりがちです。カスタマイズはコストがかかるということですね。
アウトソーシングする際のメリットとデメリット
もう1つ対極にあるのが、この「SOCサービスの利用」です。これが典型的なアウトソーシングサービスの利用になるかと思います。ログの収集・保全はサービス設備を使うということで、ログをSOCサービスに送るようなかたちになります。
ログ分析は、サービス設備とSOCサービス(を提供しています)。要するに、サービスにログ分析をお願いするというかたちですね。そうすると重要度判断もSOCサービスになります。当然、インシデント対応は自社CSIRTに対応いただくことになりますけれども、サービスも補完的に利用することができます。
そうするとメリットとしては、自組織に高スキル人材が不要になります。これがサービス利用の最大のメリットです。ただ相応の外部コストが発生するのと、サービスですのでログ保全・参照にサービス側の制限が生じる可能性があります。
それからカスタマイズに応じてくれるサービスは少ないと思いますので、制服に体を合わせるように、サービス側の対応に合わせる必要が出てくるかと思います。
この2つの手法は、当然メリット・デメリット、特徴がございますので、多くの組織が受け入れられるものではないと考えます。そこで2つの手法を組み合わせて、良いところ取りをした「ハイブリッド方式」も、環境整備方式の1つとしてご案内できるかなと思っております。
まず、ログ収集・保全は自組織の設備で対応する。そこは自前でやりながら、ログ分析ではサービスを使うわけですね。自組織の設備に貯まっているログをSOCサービスに見てもらう。重要度判断もSOCサービスに見てもらう。インシデント対応は自社CSIRTで対応しつつ、サービスに支援していただくといったハイブリッドな方法ですね。
非常にメリットが多いです。コストバランスが良く、高スキル人材はいりません。それからログ保全は自社設備でやりますので、自組織の裁量で対応できます。ログ参照に制限もありません。自組織の設備ですので、当然制限はないということになります。
唯一のデメリットは、SOCサービス利用の3つ目に書かせていただいた「サービス側の対応に合わせる必要がある」ところですが、メリットが非常に多いことがわかるかと思います。
24時間365日、ログを監視・分析するSOCサービス
これら3つの環境整備方式も一長一短がございます。よってそれぞれのメリット・デメリットを踏まえて、自組織のリソース状況に応じた選択をするのがポイントかなと思っております。ここがログ監視・分析とSOCサービス利用の勘どころになります。
では、ここからはちょっと営業的なお話になるんですけれども、当社がご提供する「MSS for ALog」をご紹介したいと思います。こちらは、最後にご紹介したハイブリッド方式に対応したログ監視・分析サービスとなります。こちらは来年の1月にリリースする予定となっております。

では簡単にサービス概要を説明してまいりたいと思います。このサービスの特徴は、お客さま環境に設置したALogを用いて、我々のエンジニアがサイバーセキュリティのログを監視するサービスです。
24(時間)/365(日)で監視します。それからインシデントの兆候となるイベントを、我々で分析して検出いたします。リスクの限定のために迅速に対応するところも、我々のサービスの特徴になります。
加えてALogを利用して、お客さま環境のログを一括して監視しますので、セキュリティデバイスの検知だけではわからない事象や影響範囲を、相関分析することで確認できます。これによって、本来お客さまがやらなければいけないインシデント運用に関する労力やコストを削減できると考えております。
このサービス導入によって、ログ保管・監視によりインシデント発生に備えた環境・体制ができることに加え、サイバーセキュリティリスクに効率的に対応する仕組みを構築できると考えております。もう1つ特徴を補足しますと、このサービスは、冒頭でご紹介した自工会ガイドラインを非常に強く意識しております。
ログ収集設備を設置すれば、インシデントから障害まで対応
では、私どもが提供するMSS fot ALogの提供イメージをご案内申し上げます。まずお客さま環境に、ログ収集設備としてALogを設置いただき、いろんなログをALogに集めていただいている環境を想定いたします。
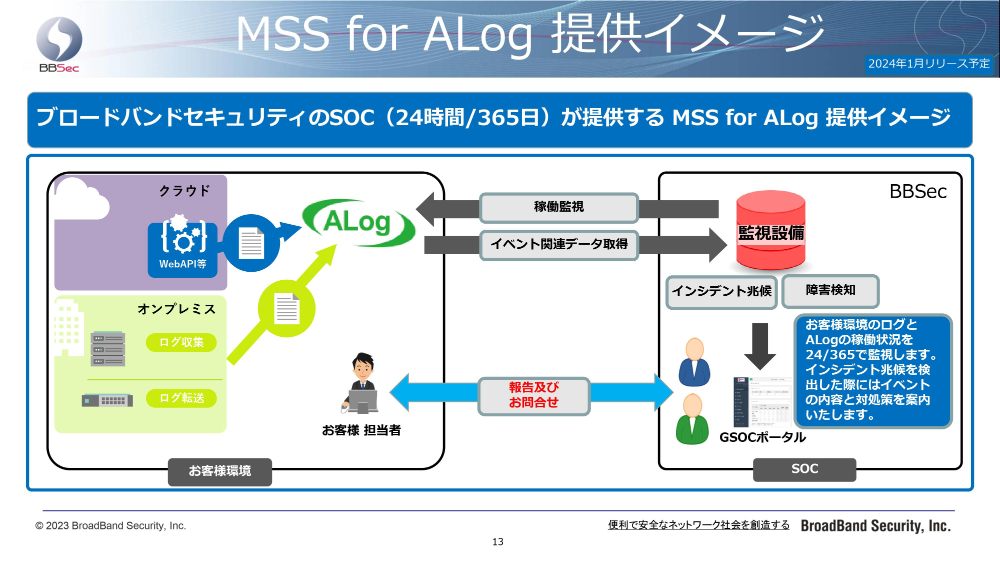
ここに私どものSOCサービスを導入させていただき、ALogの稼働監視をすると共に、イベント関連データを取得して、我々の監視設備でALogが発するイベントを監視します。
これによって、私どものSOCでインシデントの兆候や、稼働監視による障害も検知させていただきます。24時間365日で監視し、インシデント兆候が見つかった場合にはどういった対応が必要かを、私どもSOCからお客さま担当にご案内をさせていただくような提供イメージです。
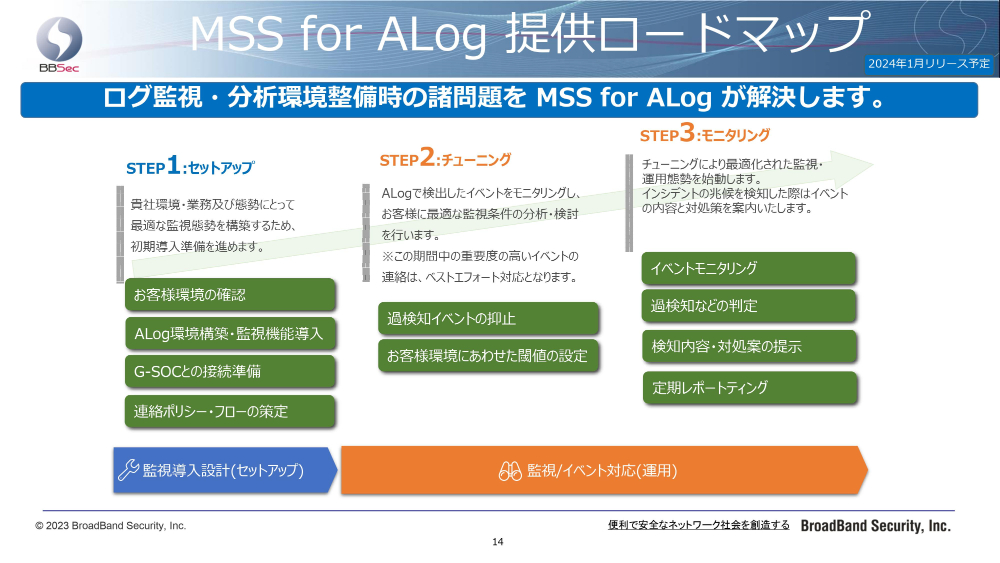
提供のロードマップとしましては、まず導入というところで、お客さま環境を確認いたします。私ども独自の監視環境・監視機能を導入し、SOCとつないでから、各種連絡ポリシー・フローを策定いたします。初期導入の準備ですね。セットアップと呼ばせていただいているのが、このステップ1になります。
監視対象のログによって異なる、2つの選択肢
次のステップ2はチューニングですね。実際に連携いただいたイベントをモニタリングして、お客さまに最適な監視条件を提供できるように分析・検討いたします。これによって過検知イベントを抑止し、お客さま環境に合わせた閾値の設定をしてまいります。
このステップ2から運用に入っていくんですけれども、チューニングの最中は非常に重要度の高いイベント連絡以外は、ベストエフォートの対応になっております。
チューニングが終わりましたら、ステップ3のモニタリングということで、実際の監視が始まります。イベントモニタリング、過検知判定、検知内容・対処案の提示、それから定期レポーティングを提供してまいります。
サービスプランは、プランAとプランBの2つをご用意しております。それぞれの違いは、監視対象ログが違うというところになります。まずプランAは、プロキシ、IPS/IDS、ファイアウォール、エンドポイントを監視対象ログとします。

プランBはさらにこの4つに加えまして、メール送受信、認証サーバー、リモートアクセス、アプリケーション操作ログ、重要システムのアクセスログ。プランBは9つのログを監視するサービスになっています。
それぞれの監視対象ログの選び方が、まさに自工会ガイドラインを意識したプランニングになっております。プランAは自工会ガイドラインのレベル2を意識しております。プランBは自工会ガイドラインでは最高のレベル3ですね。こちらの準拠を目的としたプランになっております。
それぞれプロキシ、IPS/IDS等々、監視対象ログもいろんなデバイスがあるかと思いますが、標準で対応しているデバイスをここに示しております。この標準デバイス以外にも対応できるものがいくつかありますので、こちらはお客さまの環境に合わせてご相談いただければと思います。
最も効果的な進め方は、自社と専門家による役割分担
まとめとしまして、まずログの監視・分析ですね。こちらは侵入前提のセキュリティ対策が必須と言われております。そして、ログの監視・分析の環境整備には、新たな知見・リソース・人材が必要であり、環境整備の課題となると予想されます。この課題解決には、専門家の協力を得て解決する方法を推奨いたします。

この監視・分析環境の構築・運用は、自組織と専門家が役割を分担することで、最大の投資効果を得られると考えております。その観点から、自組織のログ監視・分析環境の整備のため、私どもブロードバンドセキュリティのMSS for ALogを、ぜひともご検討いただければと存じます。
最後になりました。私どもブロードバンドセキュリティは、本日紹介したMSS for ALogのみならず、サイバーセキュリティ対策に関連したサービスを幅広くご提供しております。
サイバーセキュリティ対策に関するお悩みがございましたら、お気軽に私どもブロードバンドセキュリティにご相談いただければと存じます。ご清聴いただきまして、誠にありがとうございました。
Occurred on , Published at
からの記事と詳細 ( 企業がサイバー攻撃を「防げる」という考え方は時代遅れ 攻撃を ... - ログミー )
https://ift.tt/TNfHvi3